 颜画风的博客
颜画风的博客深度学习和其他神经网络
这个博客介绍的很详细
网址
https://www.zybuluo.com/hanbingtao/note/433855
扩散模型的
bi站教程,入门级 https://www.bilibili.com/video/BV1b541197HX/?spm_id_from=333.788.recommend_more_video.15&vd_source=6b2b1aa5a1407b74630d30ff81b19609https://github.com/yangqy1110/Diffusion-Models 这个介绍的非常详细,甚至效果非常好 https://aistudio.baidu.com/aistudio/projectdetail/4867936 这个分栏目讲了 https://openai.wiki/stable-diffusion.html
扩散模型
这里先给个jupyter文件的下载链接
CNN
- AlexNet-一个CNN结构。
- VGG-加层数,用3个3x3卷积核来代替7x7卷积核。
- ResNet,“二阶”结构,训练内容改为残差,这样可以防止网络变差。
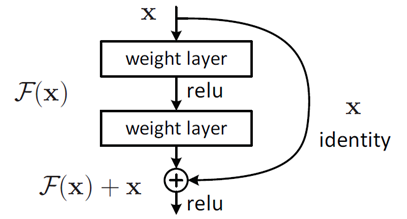
ResNet
Unet
Encoder:卷积+下采样(重复若干次),Decoder:反卷积+上采样(重复若干次)
数据预处理
图像的处理集中在像素,位置采用二维CNN来编码,相当于用窗来编码,缺点是感受野受限,一种理论认为感受野决定了它的智能程度, 依靠叠层来增加感受野不一定有效
语言的处理在于对语素进行编码,还有语言位置编码,也就是token和tokenizer
CLIP & CLAP
CLIP的英文全称是Contrastive Language-Image Pre-training,即一种基于对比文本-图像对的预训练方法或者模型。 CLAP是对Audio进行处理的类似方法
其他表示含义
Add & Norm 层:ADD表示残差层,NORM表示归一化
注意力机制
深度学习中的注意力机制通常可分为三类:软注意(全局注意)、硬注意(局部注意)和自注意(内注意)
- Soft/Global Attention(软注意机制):对每个输入项的分配的权重为0-1之间,也就是某些部分关注的多一点,某些部分关注的少一点,因为对大部分信息都有考虑,但考虑程度不一样,所以相对来说计算量比较大。
- Hard/Local Attention(硬注意机制):对每个输入项分配的权重非0即1,和软注意不同,硬注意机制只考虑那部分需要关注,哪部分不关注,也就是直接舍弃掉一些不相关项。优势在于可以减少一定的时间和计算成本,但有可能丢失掉一些本应该注意的信息。
- Self/Intra Attention(自注意力机制):对每个输入项分配的权重取决于输入项之间的相互作用,即通过输入项内部的"表决"来决定应该关注哪些输入项。和前两种相比,在处理很长的输入时,具有并行计算的优势。
自注意力机制虽然考虑了所有的输入向量,但没有考虑到向量的位置信息。在实际的文字处理问题中,可能在不同位置词语具有不同的性质,比如动词往往较低频率出现在句首。
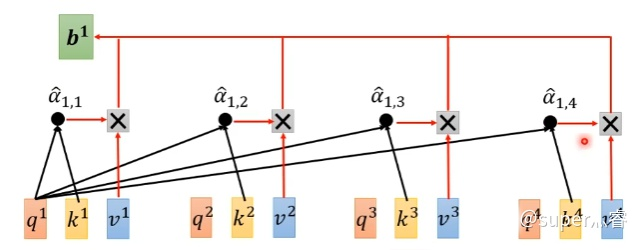
self-attention
- Query 一个随机分布
- Key 固定向量 是不是 onehot 位置也需要 onehot 编码
- Value 期望
利用 q ,k 计算 attention 的值 α ,再把所有的 α 经过 softmax 得到
q,k 的 attention 值可以采用点积、向量角度,MLP来计算
用一个例子来解释,Q 是特征信号,K 是位置编码(小波),归一化后,点积(正相关)原始信号 V
用 NLP 来解释,Q是查询向量。K是逐渐生成的句子,通常Bert中输入输出是512,qkv向量固定维度为64。V是上下文的Value,通过不停decoder(self-attension
feed-forward)就可以一个key一个key生成长句子
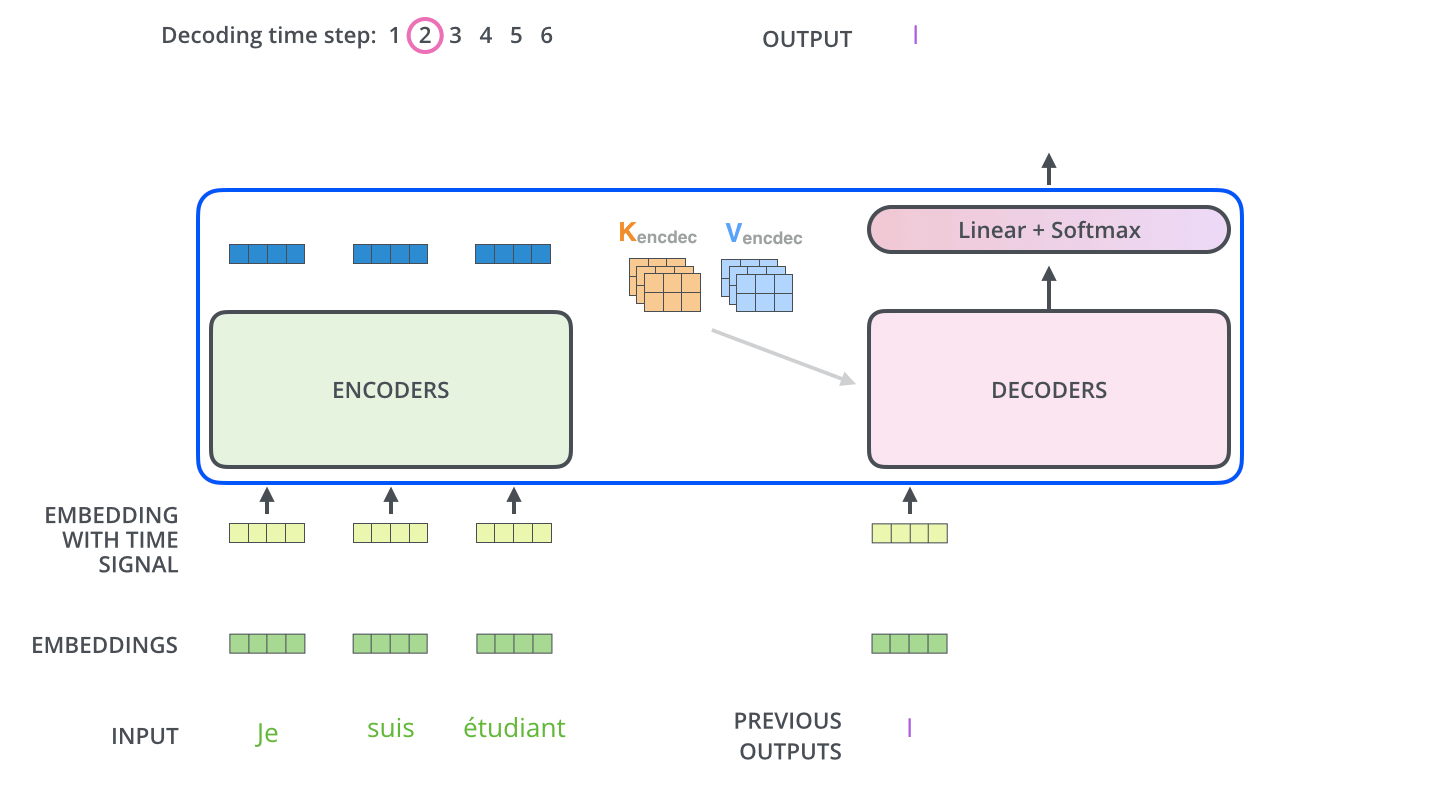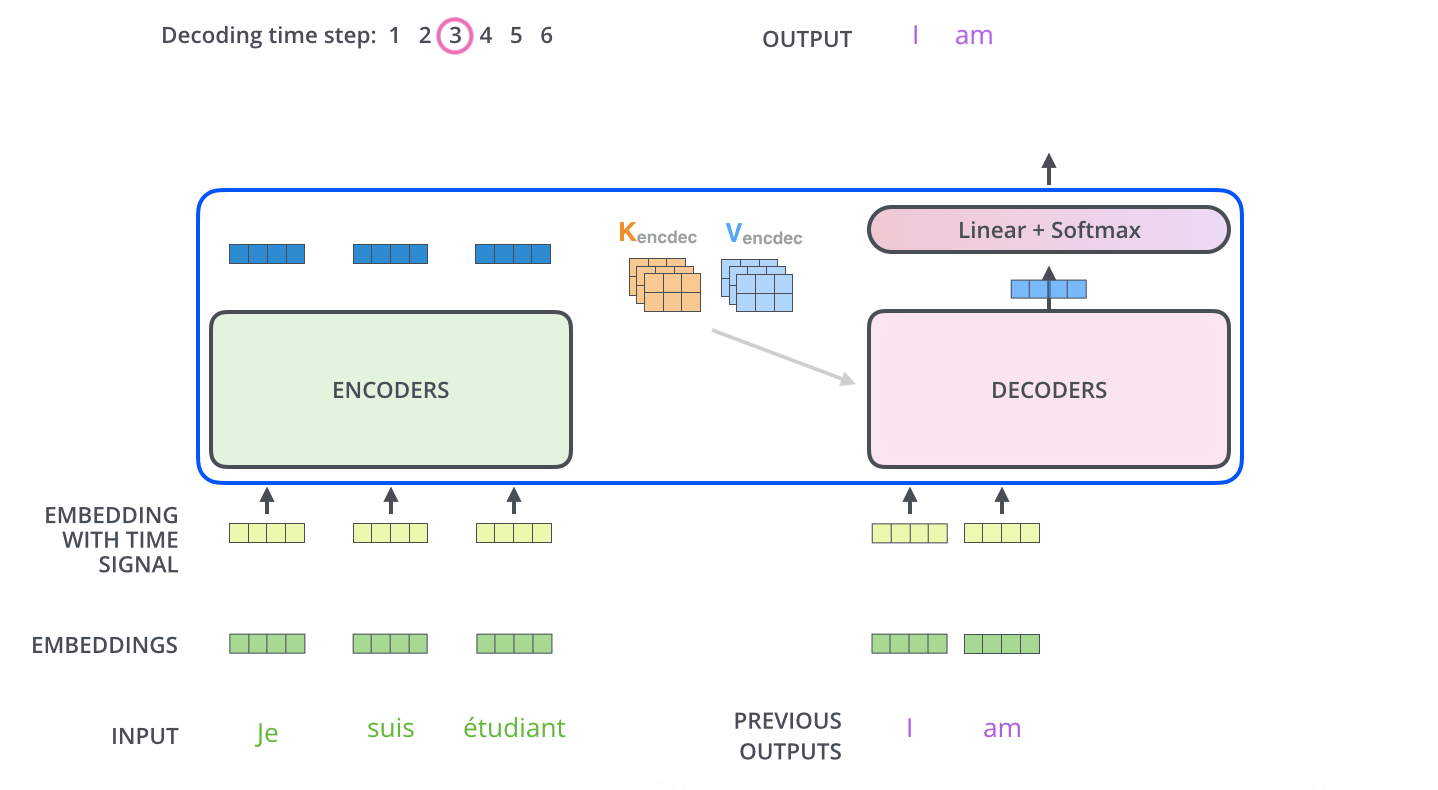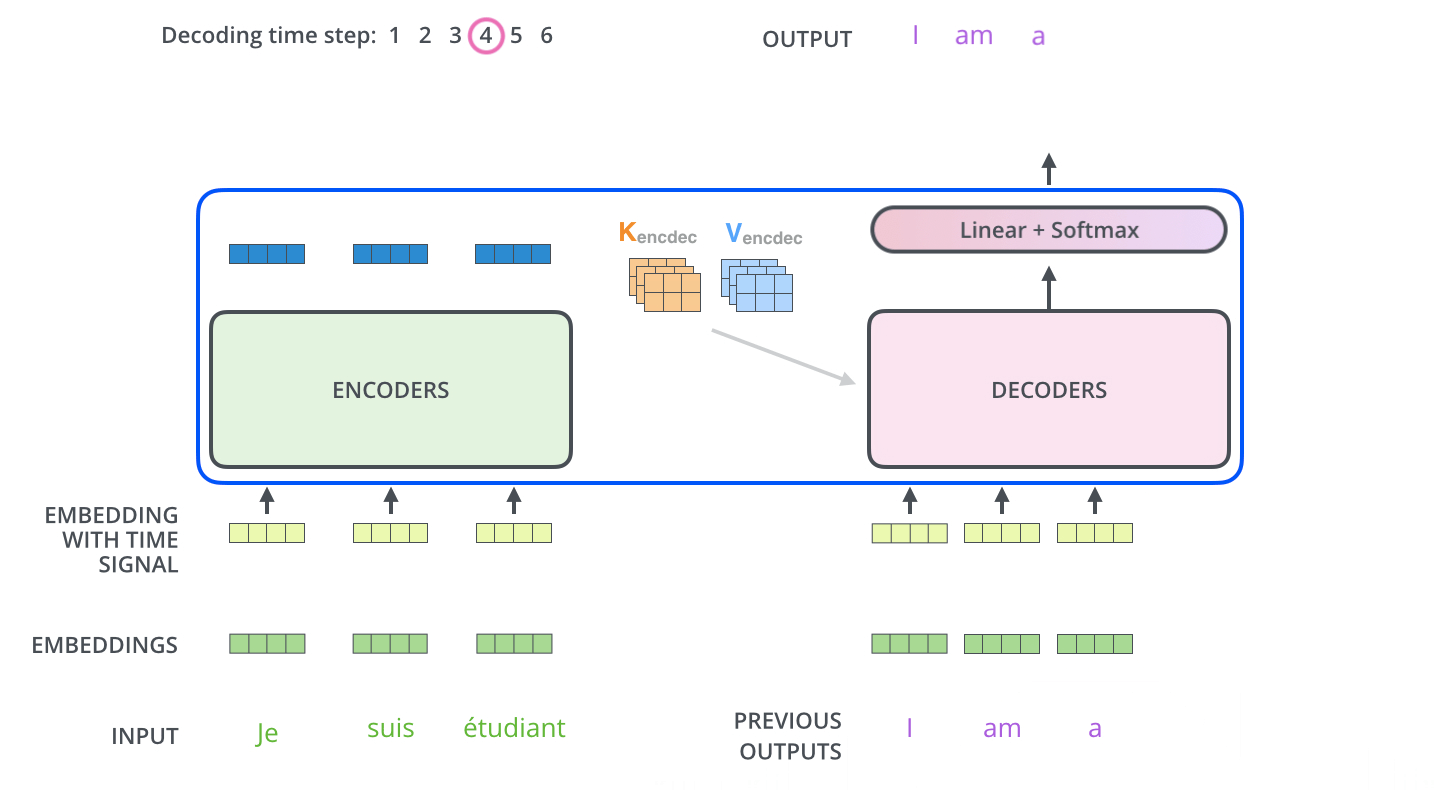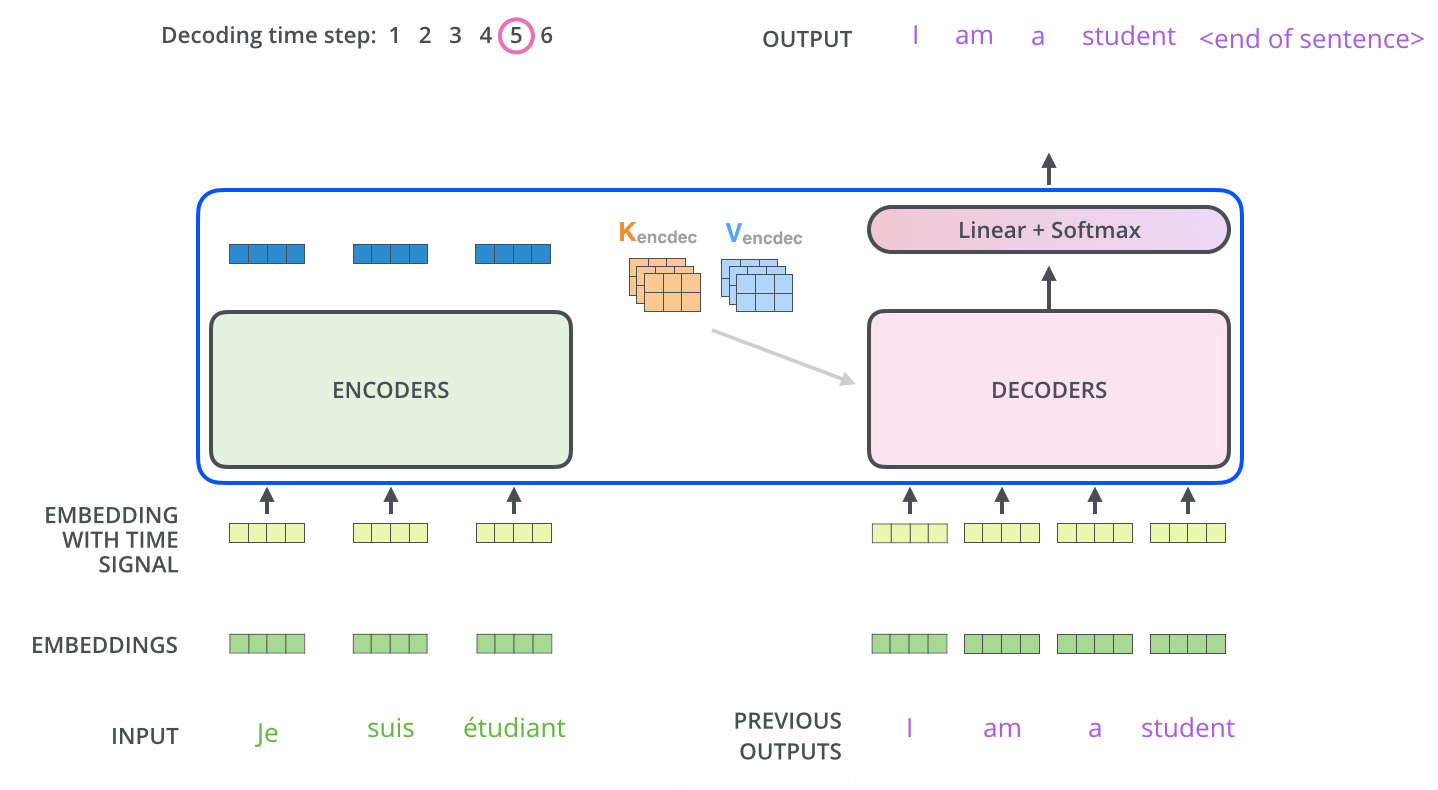
decoding
数学角度
这些网络都是线性、齐次(有通解)、一次的。
感知器
神经元也叫做感知器,任何线性分类或线性回归问题都可以用感知器来解决。感知器无法实现异或。激活函数用于实现非线性。这里的
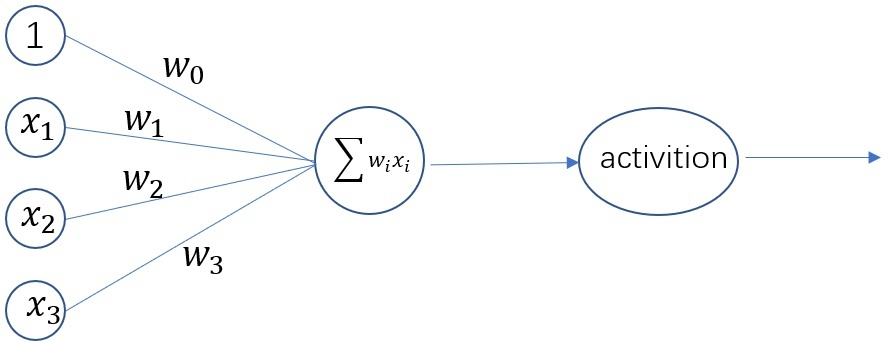
神经网络示意图
我个人的想法是若干个感知机配一对,分别训练,这样可以实现非线性效果,因为相当于将非线性区域划分了若干个线性区域。
一个常用的激活函数是
基础神经网络
首先选择激活函数:
我们假设每个训练样本为
定义Error函数:
于是
又因为
输出层:
隐藏层:
计算完
卷积神经网络CNN
首先选择激活函数(用的多)
循环神经网络RNN(Recurrent Neural Network)
语言模型是对下一个词出现的概率进行建模。那么,怎样让神经网络输出概率呢?方法就是用softmax层作为神经网络的输出层。
循环神经网络的训练算法:时序反向传播算法BPTT(Propagation Through Time)
一般来说,当神经网络的输出层是softmax层时,对应的误差函数E通常选择交叉熵误差函数,其定义如下:
权重数组W最终的梯度是各个时刻的梯度之和,即:
长短时记忆网络LSTM和GRU (Gated Recurrent Unit)
其实,长短时记忆网络的思路比较简单。原始RNN的隐藏层只有一个状态,即h,它对于短期的输入非常敏感。那么,假如我们再增加一个状态,即c,让它来保存长期的状态,那么问题不就解决了么?LSTM的关键,就是怎样控制长期状态c。在这里,LSTM的思路是使用三个控制开关。第一个开关,负责控制继续保存长期状态c;第二个开关,负责控制把即时状态输入到长期状态c;第三个开关,负责控制是否把长期状态c作为当前的LSTM的输出。
递归神经网络RNN(Recursive Neural Network)
训练算法BPTS (Back Propagation Through Structure),适合处理树状结构的语义,缺点是需要人工标注,所以不太流行。
核心:概率转移
输出: 3-
CNN 是有限感受野模型
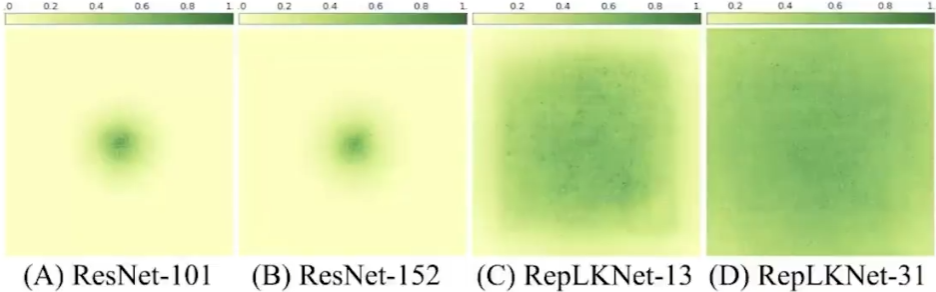
加深不能带来更大的感受野
参考文献: