颜画风的博客
颜画风的博客多任务学习
hard parameter sharing
- 底层参数统一共享,顶层参数各个模型各自独立
soft parameter sharing
- 底层参数分组加权求和,通过Gate(还是一个隐藏层)来决定到底加权
稀疏注意力模式
技术路线
transformer解码器 + Prompt-Learning文本提示学习
Instruction-tuning指示微调 +人类反馈强化学习RLHF
思维链
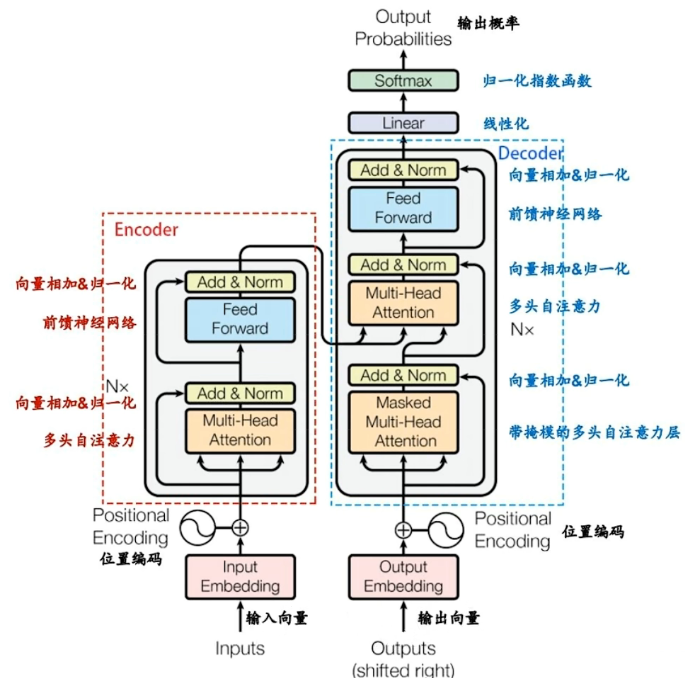
微调
结构修改(如 Lora,增加低维旁路)
模板设计(如P-tuning,更改提示词,采用提示词编码器)
GPT的无监督训练是基于语言模型的,给定无标签的序列,优化目标是最大化似然值。
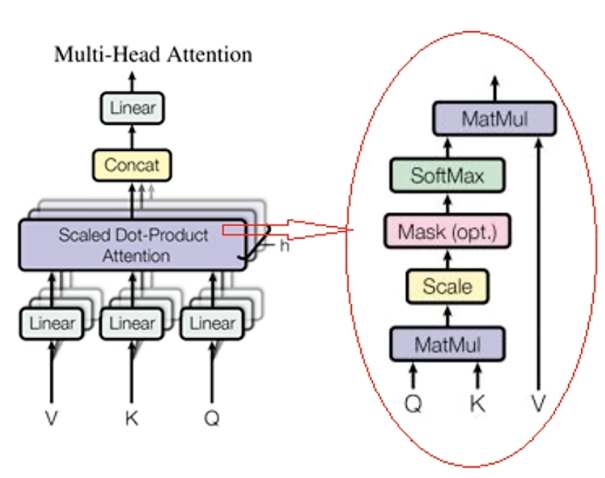
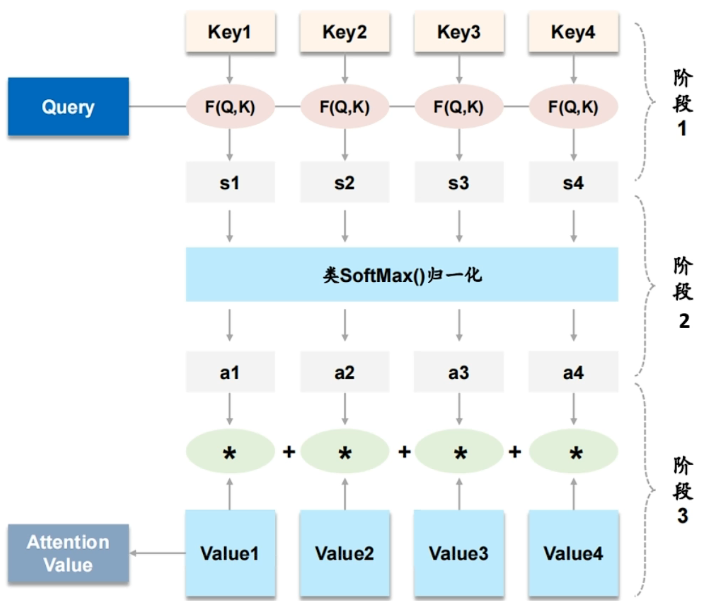
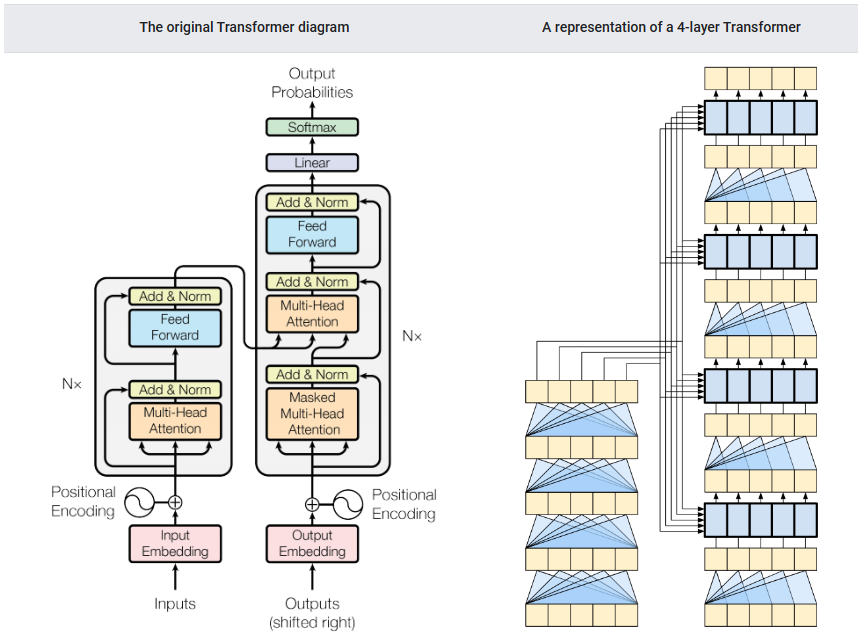
Muti-Head Attention
- 冗余掩码:不同序列长度对齐时用到
- 序列掩码:自注意力机制中用到,类似完形填空,成语接龙
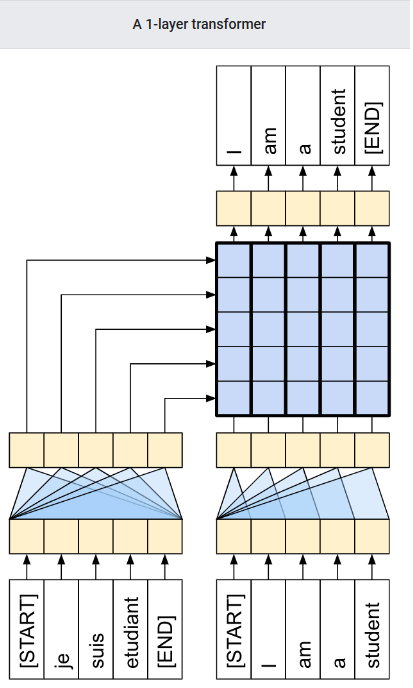
语句 i am a student 有一个根向量,与葡萄牙语对应同一个根向量,那个大矩阵就是独立的向量(我会证明它)